다른 수많은 소프트웨어 기술과 같이 Service Discovery도 이전부터 존재하던 개념이다. 그러나 최근 클라우드 및 마이크로서비스 아키텍처의 부흥과 함께 종종 언급되며 우리들의 눈에 띄는 것처럼 보인다. 한번 이번 기회에 Service Discovery에 대해 간단히 알아보자.
Service Discovery
위키피디아에서는 Service Discovery에 대한 문서가 빈약한 편이지만 간단하게 Service Discovery는 네트워크 상에서 제공되는 서비스 또는 장치의 자동 탐지라고 정의하고 있다. MSA의 입장에서 살펴보면 네트워크로 연결되어있는 여러 서비스들을 자동으로 탐지하여 그 정보들을 관리하는 것이다.
네트워크 상에 A 서비스와 B 서비스가 존재하며 각 서비스는 HTTP RESTful API를 제공한다. A가 B의 API를 사용하기 위해서는 B의 IP와 포트 같은 주소가 필요하다. 같은 물리 서버에 동작한다고해도 최소한 자신과 같은 서버에서 동작한다는 사실과 포트는 알고 있어야할 것이다. 이렇게 A가 B의 주소 정보를 구체적으로 알고 있어야 한다는 사실은 A와 B의 구조에 몇가지 제한을 만들게 된다.
첫 번째로 B를 scale-out 하는 경우를 예로 들 수 있다. B가 보단 많은 트레픽을 처리하기 위해서 scale-out을 한다고 해보자. A는 추가된 B 서비스의 서버 주소 정보를 추가적으로 알아야한다. 개발자는 직접 A에 B와 관련된 설정이 해주어야할 것이다. 만약, A 뿐만이 아니라 C, D 서비스도 B를 이용하는 있었다면 모두 일일이 새롭게 설정을 해주어야할 것이다. 설정이 별로 어렵지 않고 그정도는 직접 해줘도 괜찮다고 할 수도 있다. 그렇다면 auto scale-out은 어떻게 해야할까? 들어오는 트레픽에 비례해서 자동으로 B의 인스턴스가 추가된다고하면 A, C, D는 어떻게 할 것인가? B 서비스가 별도의 로드밸런서에 연동되어 자동으로 부하분산을 해주고 있다고해도 역시 개발자가 직접 로드밸런서에 새롭게 추가된 추가적인 B 인스턴스에 대해서 설정을 해주어야하는 번거로운 작업이 존재한다.
두 번째로 클라우드 환경에서는 IP 같은 주소 정보가 매우 동적이라는 것이다. 어찌보면 위에서 잠깐 언급한 auto scale-out와 이어지는 이야기일 수도 있다. 클라우드 환경에서는 서버 인스턴스가 얼마든지 실시간으로 간단하게 추가 및 제거될 수 있다. 이 과정에서 부여받는 주소 정보는 예측이 불가능하다.
Service Discovery는 클라이언트가 주소를 명시적으로 알고 있어야한다는 제한점으로부터 우리를 해방시켜준다. Service Discovery는 서비스들의 주소를 자동으로 탐지하고 관리를 해주기 때문이다. Service Discovery에 의해 주소 정보가 관리되기에 클라이언트는 더 이상 서버의 주소 및 포트에 대해서 알 필요가 없으며 어떤 서비스가 존재한다는 것만 알면 된다. 다른 서비스와의 통신에 좀 더 추상화된 레이어를 제공한다고 볼 수 있다. 또한, 서버 측도 서비스 주소를 자동으로 탐지하여 관리하기에 보다 물리적인 인프라에 제약을 받지않고 다이나믹하게 서비스를 운영할 수 있다.
Service Registry
Service Discovery에서 네트워크 내의 각종 서비스에 대한 주소 정보를 저장하고 관리하는 중앙 서버를 Service Registry라고 부른다. 다른 서비스들의 주소 정보를 제공하므로 고가용성이 요구되지만 최신 Service Discovery 플랫폼들은 만에 하나 Service Registry가 죽어버리더라도 문제없이 서비스들 간에 통신이 가능하도록 방법을 제공하기 때문에 부담은 덜하다.
Pattern
Service Discovery는 크게 두가지 패턴을 가지고 있다. 하나는 Client-Side Discovery Pattern이며 나머지 하나는 Server-Side Discovery이다.
Client-side Discovery
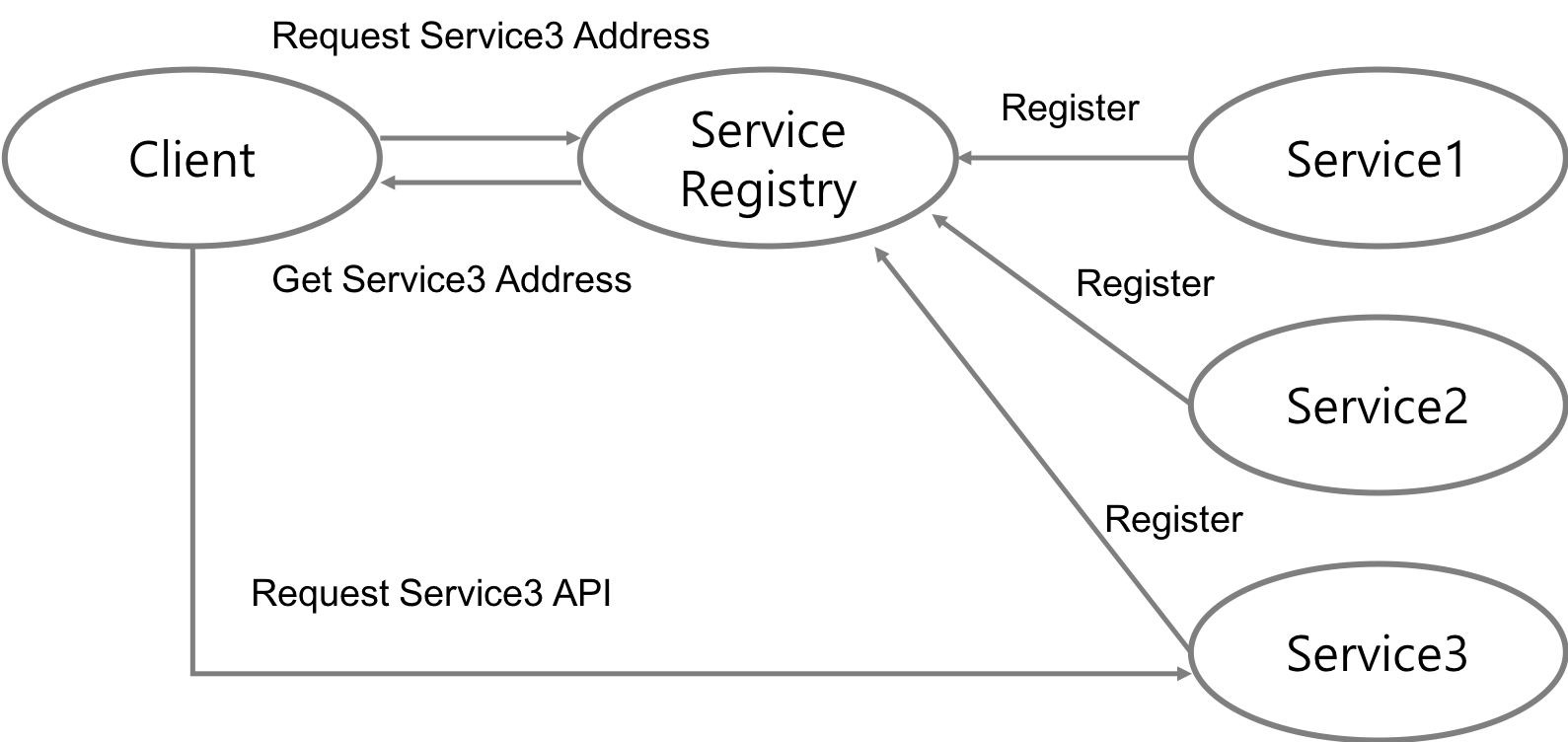
클라이언트가 직접 Service Registry로부터 특정 서비스의 주소 정보를 받아와서 통신을 하는 패턴. 클라이언트가 직접 주소를 가져와서 서비스와 직접 통신을 하기 때문에 불필요한 네트워크 부하를 줄일 수 있다. 또한, 클라이언트가 특정 서비스의 모든 인스턴스 주소를 알 수 있기 때문에 자신인 원하는대로 로드밸런싱을 할 수도 있다. 단 이점은 단점이 되기도 하는데, 자신이 서비스 주소를 가져오고 원하는대로 로드밸런싱을 할 수 있다는 말은 클라이언트가 Service Discovery를 위한 추가적인 기능을 개발해야된다는 말이기 때문이다.
Server-side Discovery
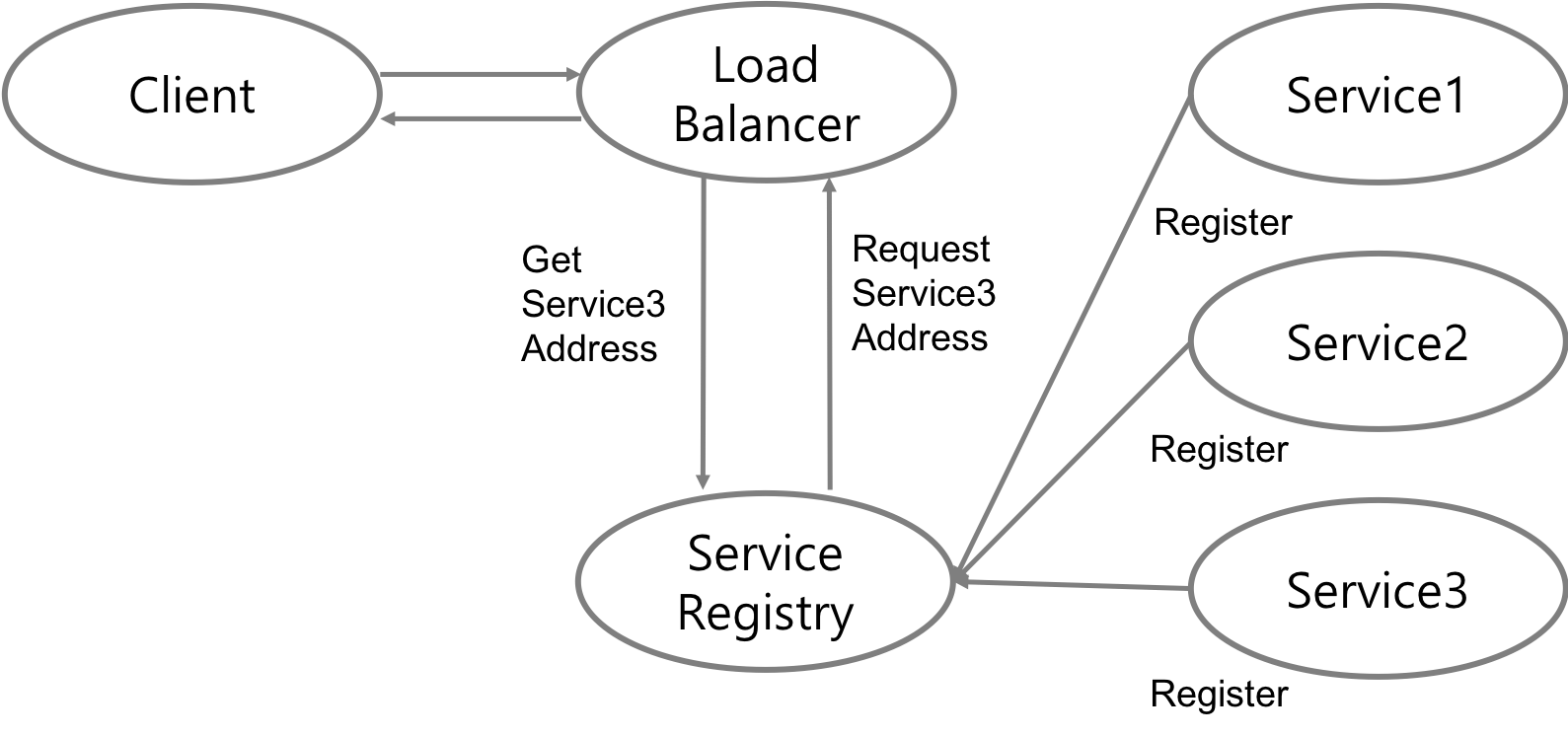
이 패턴은 클라이언트가 Service Registry에 대해서는 전혀 몰라도 되는 패턴이다. 서버와 클라이언트 사이에는 요청 유형에 따라(예를 들어, URL 경로 등) 적절한 서비스 인스턴스로 전달을 해주는 라우팅 서버가 존재한다. 이 라우팅 서버는 Service Registry를 참고하여 서비스에 대한 주소 정보를 얻고 이를 바탕으로하여 클라이언트로부터의 요청을 서비스 인스턴스에 전달한다. 클라이언트는 로드밸런서와만 통신을 하기 때문에 따로 Service Discovery와 관련된 특별한 작업을 신경 쓸 필요가 없다. 하지만 로드밸런서는 SPOF(Single Point Of Failure)가 될 수 있기 때문에 매우 중요한 요소로서 높은 고가용성이 요구될 것이다.
Next - Service Discovery 구현체
다음 포스트에서는 Service Discovery 구현체를 몇가지 알아볼 것이다. 첫 번째로 Java로 개발된 Netflix의 Eureka에 대해서 알아보고, 두 번째로 Go로 개발된 HashiCorp의 Consul 이렇게 두 가지를 알아볼 것이다.